
Vom 20. bis 22. Januar fand mal wieder ein Storage Field Day statt: Eingeladene Delegierte diskutieren ein paar Tage lang mit Herstellern über Technologie und neue Produkte. Zu Talks und Diskussionen gibt es einen öffentlich zugänglichen Live-Stream, nur direkt mitdiskutieren kann man so nicht. Ursprünglich trafen sich die Delegierten dazu im Silicon Valley und besuchten reihum die teilnehmenden Hersteller. In Zeiten von Pandemie wird natürlich auch diese Veranstaltung als Online-Event gestaltet.
Unser Technology Scout Wolfgang nahm sich vergangene Woche die Zeit, um live dabei zu sein. Fragen stellen und mitdiskutieren ist in Grenzen auch „von außen“ möglich, jeder Tech Field Day hat dazu einen eigenen Twitter-Hashtag (hier: #SFD21), worüber Delegierte, Firmenvertreter, Veranstalter und eben Zuschauer kommunizieren. Weil die Veranstaltung normalerweise in Kalifornien statt findet, und die meisten der beteiligten (und dafür bezahlenden Unternehmen) ihren Firmensitz auch dort haben, gilt amerikanische Westküstenzeit. Hier in Mitteleuropa ist das dann in den Abendstunden, so von 17:00h bis Mitternacht. Entsprechend anstrengend gestaltete sich, jeden Tag bis zum Ende dabei zu bleiben.
Grundtenor der drei Tage: Alles ist oder wird irgendwie Cloud native, Kubernetes ist Trumpf, nach serverless compute kommt jetzt storageless data, und Storage-Hardware wird langsam schneller, als die CPU liefern kann.
Tag 1 – MinIO und Tintri
Den Auftakt am Mittwoch machte MinIO. Kern der Lösung ist ein Object Storage mit dem Designziel, als Primärspeicher herhalten zu können. Entsprechend viel Aufwand steckt in den performancekritischen Bereichen des Codes. Das Produkt ist von Grund auf neu entwickelt, das Unternehmen existiert erst seit fünf Jahren. MinIO kann man alleinstehend betreiben, seine Stärken spielt es aber erst zusammen in einer orchestrierten Container-Umgebung unter der Obhut von Kubernetes aus. VMware ist ein Design-Partner von MinIO, darüber wird sichergestellt, dass sich der MinIO Object Storage auch nahtlos in eine vSAN-Umgebung einfügt.
Den Mittwoch Abend bestritt Tintri. Deren Ausführungen konnte ich leider wegen Terminüberschneidung nur mit einem halben Auge folgen. Es ging in teilweise technischer Detailtiefe um neue Werkzeuge zur Performance-Analyse von Tintri Storage-Systemen.
Tag 2 – NetApp und Nasuni
Am Donnerstag macht NetApp den Anfang. Dort ging es zunächst um die Analyse langsamer Datenbank-Queries, insbesondere bei Oracle. Unter Branchenkennern nicht neu: Wir sind bei der Performance von Storage-Systemen mittlerweile in Bereichen angekommen, wo langsame Datenbank-Queries zu einem echten Problem werden, weil die sich nicht mehr mit schnellerem Storage übertünchen lassen. NetApp gibt dazu den Datenbank-Programmierern Werkzeuge an die Hand, um Schwachstellen im Datenbank-Layout zu erkennen und SQL-Queries so zu optimieren, dass sie optimal mit dem darunter liegenden Storage-Layout zusammen wirken können. Daneben stellte NetApp sein Data Science Toolkit vor. Zielgruppe sind Data Science Engineers, die mit Python arbeiten (Jupyter, Kubeflow, Apache Airflow oder direkt an der Kommandozeile). Mit dem Toolkit wird es durch einfache Library-Calls direkt aus dem Quellcode möglich, die zur Berechnung notwendigen Volumes direkt aus dem Code heraus zur Laufzeit im Storage zu erzeugen, zu verwenden und den Plattenplatz am Ende auch wieder freizugeben. Das Toolkit ist quelloffen und auf Github verfügbar.
Die zweite Hälfte des Donnerstagabend bestritt Nasuni. Und obwohl es den Hersteller schon seit etlichen Jahren gibt, war er mir bis vor ein paar Tagen unbekannt. Die Idee ist einfach: Man nehme beliebige Storage Buckets bei (nahezu) beliebigen Cloud-Anbietern. solange sie nur S3 als Protokoll unterstützen. Darüber lege man einen Abstraktionslayer (im konkreten Fall UniFS), aus dem sich dann Clients Freigaben mounten können, wie man das von einem NAS gewohnt ist. Nasuni verweist dabei insbesondere auf Funktionen von Cloud-Storage, die sonst nur in kostspieligem Enterprise Storage verfügbar sind: Redundanz, Replikation (und dadurch auch eine gewisse Lokalität), eingebautes Backup/Recovery, ggf. Deduplikation und Verschlüsselung.
Tag 3 – Hammerspace, Pliops, Intel
Tag 3 beginnt ähnlich, wie Tag 2 endete: mit Storageless Data, dieses Mal in der Geschmacksrichtung Hammerspace. Besonderen Wert legt man dabei auf Data Gravity: Weil man Replikation in der Cloud benutzt, ist es möglich, Daten dorthin zu verlagern, wo sie gebraucht werden. Ganz besonders interessant wird das natürlich, wenn man nicht nur Daten in der Cloud hält, sondern auch die Rechenleistung. Ähnlich wie bei Nasuni erfolgt der Zugriff wie bei einem NAS, aktuell werden NFS und SMB unterstützt. Was mir insbesondere gefiel: wenn der CEO David Flynn trotz Online-Veranstaltung und Webcam mal eben ans Whiteboard geht um ein paar unvorbereitete Details zu erläutern.
Zu Aufbau, Funktion, Anwendung und den verschiedenen Geschmacksrichtungen von Storageless Data haben wir bereits einen technischer Artikel in Vorbereitung.
Zum Abschluss der drei Tage Storage Field Day kommt dann aber doch endlich auch Hardware. Zunächst zeigte die noch junge Pliops (gegründet 2017) die Ideen hinter ihrem Pliops Storage Processor.
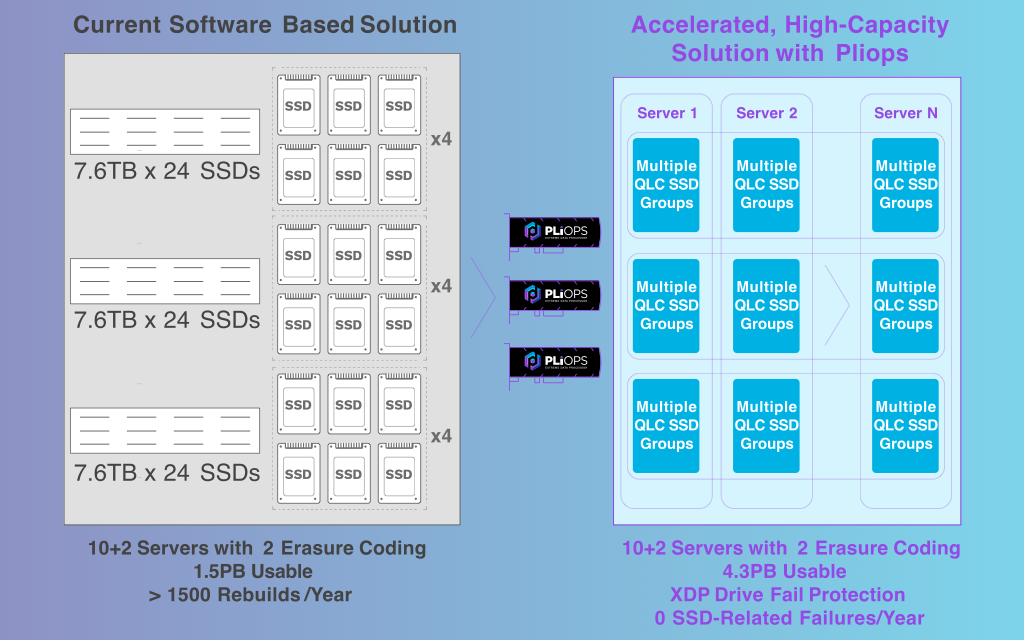
Gründer und Team rekrutieren sich aus verschiedenen, bekannten Flash- und Storage-Herstellern. Das Unternehmen kommt aus Israel, von dort kennt man eine Reihe anderer, erfolgreicher und innovativer Storage-Hersteller. Besagter Storage Processor arbeitet im Datenpfad zwischen CPU und Flash/SSD und leistet dort allerlei Magie auf ineffizienten Datasets. Das Unternehmen verspricht, damit Flash-Kapazität besser zu nutzen als mit herkömmlichen RAID-Ansätzen, und man holt auch mehr Performance aus Flash-Modulen, als ohne Karte. Aktuell wird nur Linux unterstützt, VMware ist geplant, jedoch noch ohne konkreten Termin. Die Karte wird angesprochen als NVMe Block-Device und versteht alternativ auch ein Key-Value-API (z. B. in Zusammenarbeit mit RockDB). Für mich spielt das Device in der Gruppe des Computational Storage, manchmal auch Data Processing Unit genannt (DPU). So ganz habe ich den besonderen Clou in den zwei Stunden aber auch noch nicht verstanden, hier ist noch etwas Nacharbeit notwendig.
Zum Abschluss der drei Tage stand dann noch Intel auf dem Programm. Nachdem Intel kürzlich die Fertigung ihrer NAND-Flash-Module an SK hynix verkaufte, konzentriert sich der Chip-Bäcker jetzt ganz auf Phase Change Memory aka 3DXpoint aka Optane aka PMEM (für Peristent Memory). Weil Intel erst vor wenigen Wochen ausführlich im Rahmen der Memory & Storage Moment 2020 über neue Hardware sprach, gab es dieses Mal nur eine Reihe Customer Stories mit den jeweils beteiligten Engineers von Intel, von den entsprechenden Kunden und ggf. auch von Intel-Partnern. Natürlich sind die präsentierten Performance-Ergebnisse oder wahlweise Kosteneinsparungen beeindruckend bis riesig. Wären sie es nicht, wären das auch alles keine Customer Stories. Ich finde diese Geschichten immer etwas langweilig, und ähnlich wie Best Practices sind sie nur in den seltensten Fällen auf die eigene Umgebung anwendbar. Die Sinnhaftigkeit verschließt sich mir deshalb etwas. Als Abschluss zu drei Tagen vollgepackter Storage-Technologie waren die Kundengeschichten aber ein durchaus willkommener Ausklang.
Der Storage Field Day 22 wird Anfang August 2021 statt finden. Noch sind keine Sponsoren bekannt, wir werden aber sicher wieder davon berichten. Bis dahin gibt es noch eine Reihe anderer Field Days. Reinschauen lohnt sich.

