

Für die neue Episode vom data://express haben wir uns Gartners neuen HCI-Quadranten angeschaut, uns über den State of Storage Security Report von Continuity erschrocken, neue Features in OpenZFS gefunden und weisen auf die Wichtigkeit von Backups für SaaS hin.
Gartner Magic Quadrant HCI Software 2021

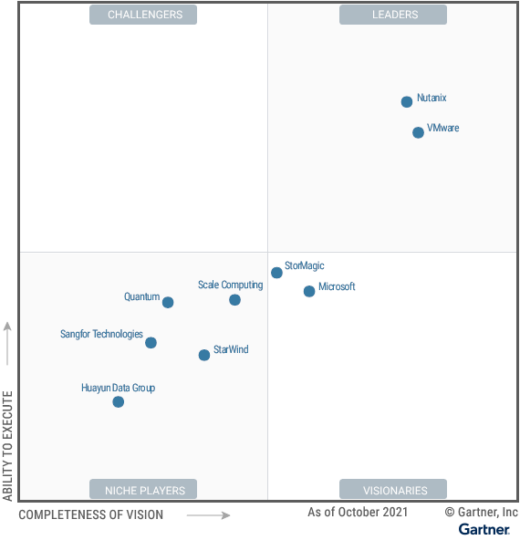
Gartner hat Mitte November 2021 die nächste Version des Magic Quadrant zu Software für Hyperconverged Infrastructure veröffentlicht. Mit dabei auch dieses Mal: Nutanix, VMware, StorMagic, Microsoft, Scale Computing, StarWind, Quantum (Pivot3), Sangfor Technoligies and Huayun Data Group. Eine Reihe bekannter Herteller von HCI-Software ist nicht dabei, was die Aussagekraft des Magic Quadrant leider etwas eintrübt. Während DataCore vor einem Jahr noch mit von der Partie war, hat es dieses Mal nicht gereicht: „DataCore was unable to meet inclusion criteria.“ Welche Kriterien das im Detail waren könnten wir bestenfalls raten, das wäre aber nicht seriös.
Die meisten der bewerteten Hersteller ordnet Gartner ein in die Kategorie Niche Player. Abgeleitet aus der Beschriftung der Achsen des Magic Quadrant könnte man dort hinein interpretieren: Nischenplayer haben keine eigene Produktidee und bauen einfach nach, was andere vorbauen (Completeness of Vision). Außerdem finden sie nicht genug Kunden, um ihre Produkte in den Markt zu bekommen (Ability to Execute). Es kann aber auch einfach daran liegen, dass die Nischenplayer ganz absichtlich spezielle Marktbedürfnisse abdecken, und es gar nicht auf den großen Massenmarkt abgesehen haben.
Wie im Vorjahr sieht Gartner als Leader Nutanix und VMware. Beide haben ein umfangreiches Ökosystem im Bereich Virtualisierung und HCI. Während VMware weit in den Rechenzentren dieser Welt verbreitet ist, und insbesondere Windows-Servern bei der Virtualisierung auf die Sprünge half, ist Nutanix als Produktbundle im Lieferprogramm von HPE, Lenovo Fujitsu und auch als AWS EC2-Instanz zu bekommen. Das eröffnet eine breite Käuferschaft und damit eine starke Ability to Execute.
Mit Scale Computing hatten wir bei data://disrupted® in der Vergangenheit schon mehrfach zu tun. Im April 2021 sprachen wir mit Thorsten Schäfer, Regional Sales Manager DACH/SE/EE bei Scale Computing, über Produkte, Lösungen, Hyperconverged Infrastructure (HCI) und Lieblingskunden.

Der Zielmarkt von Scale Computing ist insbesondere Virtual Desktop Infrastructure und HCI am Edge. Entsprechend handlich und simpel zu bedienen sind deren Appliances („Das Smartphone unter den HCI-Lösungen.“). Wer dazu tiefer eintauchen möchte:
- Scale Computing Presents at Tech Field Day 20
- Präsentation auf dem data://disrupted® Summit 2020: HCI einfach einfach! IT-Infrastruktur wie ein Smartphone!
- Vendor Showcase-Page Scale Computing
State of Storage Security 2021
Continuity hat Schwachstellen und Fehlkonfigurationen in Enterprise-Storage-Umgebungen untersucht und in einem Report zusammengefaßt. Die anonym analysierten Daten decken unterschiedliche Speicherhersteller und -modelle ab. Zu den größten Risiken gehören die Verwendung veralteter Software, Protokolle oder Schnittstellen, Konfigurationsfehler und Nachlässigkeit bei den Nutzerrechten. Zu den analysierten Herstellern gehören u.a. Dell EMC, IBM, Hitachi Data Systems, Cisco, Brocade und NetApp. Den kompletten Stae-of-Storage-Security-Report gibt es auf der Webseite von Continuity zum Download.
Uns gab der Report ausreichend Anlass, die Tipps der Woche der Speicher- und Datensicherheit zu widmen:
- Update, update, update: Wenn es Patches oder neue Versionen für Software, Schnittstellen oder Protokolle gibt, dann nutzt die bitte auch! Wenn ihr damit überfordert seid oder es an Fachkräften mangelt, sucht euch Hilfe von Experten.
- Nutzerrechte einschränken: Auch wenn es unbequem ist – richtet für jeden Admin einen eigenen User ein. Rollenmodelle helfen bei der Verwaltung. Nicht jeder muß immer alles können und dürfen. RBAC ist seit den 90ern des letzten Jahrtausends etabliert. Neu an Zero Trust Network Access ist wirklich auch nur das Buzzword, die Technologie dazu gibt’s schon ein paar Jahre.
- Automatisierung bis zum Umfallen: Komplexe Infrastrukturen erfordern intelligente Maßnahmen. Vor Konfigurationsfehlern schützen AIOPS. Mit ChatOPs behaltet ihr alles wichtige im Blick und könnt schnell reagieren. Wer heute noch glaubt, seine Infrastruktur mit Turnschuhen im Griff zu haben, ist wirklich selber Schuld an Verlust oder Manipulation seiner Daten.
- Klassifizierung und Segmentierung: Nicht nur das BSI predigt seit Jahren, dass Unternehmen ihre Daten klassifizieren und segmentieren sollen. Kein noch so wichtiger Mitarbeiter braucht wirklich Zugriff auf alle Daten seiner Firma. Nein, auch nicht der CEO! Alles zum Need-to-Know-Prinzip findet ihr im PDF „Leitfaden für Informationssicherheit“ auf den Webseiten des TÜV Rheinland.
- Multi Everything: Ein wichtiger Baustein in der IT-Sicherheit ist Redundanz. Das beginnt bei der Ausfallsicherheit und hört nicht bei Backups auf. Größtmöglichen Schutz erreicht ihr mit Vielfalt. Dank Software Defined Storage sind Multi-Vendor-Plattformen keine Herausforderung mehr. Hersteller-Redundanz beinhaltet oft auch Technologie-Redundanz. Multi-Cloud kann Daten retten. Holt Euch Hilfe von Experten wie z. B. der Cristie Data GmbH – die konzentrieren sich seit 50 Jahren auf die Sicherheit und intelligentes Management von Unternehmensdaten.
OpenZFS Summit 2021 und AWS FSx OpenZFS
Anfang November war OpenZFS Developer Summit und zwei Wochen später hat Amazon hat auf ihrer re:invent 2021 angekündigt, jetzt auch OpenZFS im Rahmen von AWS FSx anzubieten. Für uns Grund genug, um im Podcast etwas umfangreicher auf OpenZFS einzugehen.
Seit 2020 spricht man in der ZFS-Versionierung nicht mehr von Feature Flags, sondern nutzt „normale“ Versionsnummern. Ursprünglich war geplant, jedes Jahr ein Nuller-Release zu bringen, beginnend mit OpenZFS 2.0 in 2020. Grund ist insbesondere eine Restrukturierung der Entwicklung. Nachdem Sun von Oracle gekauft wurde und ZFS als quelloffene Software OpenZFS in der Community außerhalb von Oracle weiter entwickelt wurde, war Illumos die treibende Kraft hinter neuen Features. ZFS on Linux (ZoL), ZFS auf FreeBSD und ZFS on OSX basierten auf Illumos-Code, ebenso wurde das OpenZFS-Repository daraus befüllt. Mit OpenZFS 2.0 ist mittlerweile das OpenZFS-Projekt das zentrale Repository und zugleich die gemeinsame Version für Linux und FreeBSD. Illumos und ZFS on OSX bedienen sich aus diesem Code. Für Open ZFS 3.0 ist eine weitere Integration geplant, dann wird voraussichtlich nur noch Illumos eigene Änderungen an OpenZFS-Code durchführen. Alle anderen Betriebssysteme bauen dann auf identischer Codebasis von OpenZFS auf. Im Podcast sind diese Zusammenhänge übrigens versehentlich falsch erläutert, also bitte nicht verwirren lassen. OpenZFS soll in 2021 veröffentlicht werden, was in den letzten drei Wochen des Jahres aus unserer Sicht aber eng wird.
Auf dem Developer-Summit gab es eine Reihe interessanter Vorträge zu Funktionserweiterungen für ZFS, die in aktuellen Storage-Umgebungen sinnvoll sind. So hat ZFS jetzt ein richtiges DirectIO. Bisher gab es zwar ein solches Setting, das blieb aber wirkungslos. DirectIO hebelt alle Caches aus und ist insbesondere bei Datenbanken sinnvoll, die eigene Caching-Strategien mitbringen. Außerdem profitieren Anwendungen, die große Menge Daten schreiben, ohne Absicht diese Daten jemals wieder lesen zu wollen. Das gilt insbesondere beim Checkpointing von Datenbanken oder von lange laufenden HPC-Anwendungen. Auch ein Setup mit NVMe als VDEV kann mit DirectIO bis zu 3x schneller werden.
Datacore hat sich ZFSin angenommen, der ZFS-Implementierung für Microsoft Windows. Zunächst musste mehr Stabilität in den Code, um anschließend an der Performance arbeiten zu können. Je nach eingeschalteten und konfigurierten Features erreicht ZFSin jetzt zwischen 65% .. 5700% mehr Bandbreite bei spürbar verbesserter Latenz. Wer sich fragt, weshalb ausgerechnet Datacore: deren SANsymphony basiert auf einem Microsoft Windows Kernel. Arbeiten an ZFSin sind also nur konsequent, zumindest sofern man dort über den zukünftigen Support von OpenZFS nachdenkt.
Moderne Storage Hardware – konkret Persistent Memory – hat verglichen zu allen anderen Storage Devices eine sehr geringe Latenz. Die bisherige Funktionsweise des ZIL (ZFS Intent Log, der Schreibcache) kann diese Latenz nicht nutzen und kann so zum Flaschenhals in einem System werden. Der Datenpfad bremst ZFS deutlich aus, wenn Persistent Memory für ZFS genutzt wird. Mit einer am Developer Summit vorgestellten, neuen Implementierung des ZIL ist eine bis zu 8-fache Verbesserung des Durchsatzes möglich im Vergleich zur vorherigen Implementierung.
Weitere Konferenzbeiträge beschäftigten sich mit ZFS für Object Storage, einer speziellen Cache-Implementierung ZettaCache, Verbesserungen des Replikations-Mechanismus zfs send|recv, logischen Quotas, sowie der Möglichkeit, an VDEVs Properties zuweisen zu können. Zu allen Konferenzbeiträgen sind Slides und die Video-Aufzeichnung auf der Webseite zum OpenZFS Developer Summit 2021 verlinkt.
Einigermaßen überraschend für uns kündigte Amazon auf ihrer diesjährigen re:invent an, dass OpenZFS ab sofort im Rahmen von Amazon FSx als eines von insgesamt vier optionalen Dateisystemen verfügbar wäre. Mit Lustre, NetApp ONTAP und Windows File Server ist OpenZFS hier sicher in guter Gesellschaft. Allerdings ist das in der Praxis alles nur noch halb so schön: Das Filesystem wird einzig über ein WebGUI konfiguriert und administriert. Eine Reihe ZFS-Optionen sind dort zwar verfügbar, aber eben längst nicht alle. Wer es gewohnt ist, sein Filesystem von Hand feinzutunen (was bei OpenZFS zumeist unnötig ist), wird sich hier schnell frustriert abwenden. Dazu kommt, dass man das Filesystem auf Client-Seite nur per NFS-Mount benutzen kann, aber weder einen ZPool nativ importieren noch ein Filesystem nativ an eine VM mounten kann. Eine Reihe der Vorteile von ZFS bleiben so leider für den Betrieb auf der Strecke. Immerhin: bei NFS ist Amazon nicht geizig und unterstützt gleichermaßen NFS v3, v4.0, v4.1 und v4.2.
Wenn du mehr wissen willst:
- ZFS – Was ist das und wie nutze ich das? – Talk von Sebastian Mohr, Geschäftsführer Mibes IT, auf dem data://disrupted® Summit im Oktober 2020
- OpenZFS Developer Summit 2021 – Die Seite zum Summit mit allen Präsentationen und Video-Auzeichnungen der Talks.
- New – Amazon FSx for OpenZFS – Der Blog-Post umreißt die Funktionen von Amazon FSx for OpenZFS und zeigt anhand einer größeren Anzahl kommentierter Screenshots die Konfiguration.
SaaS Application Data Protection, 4Q21

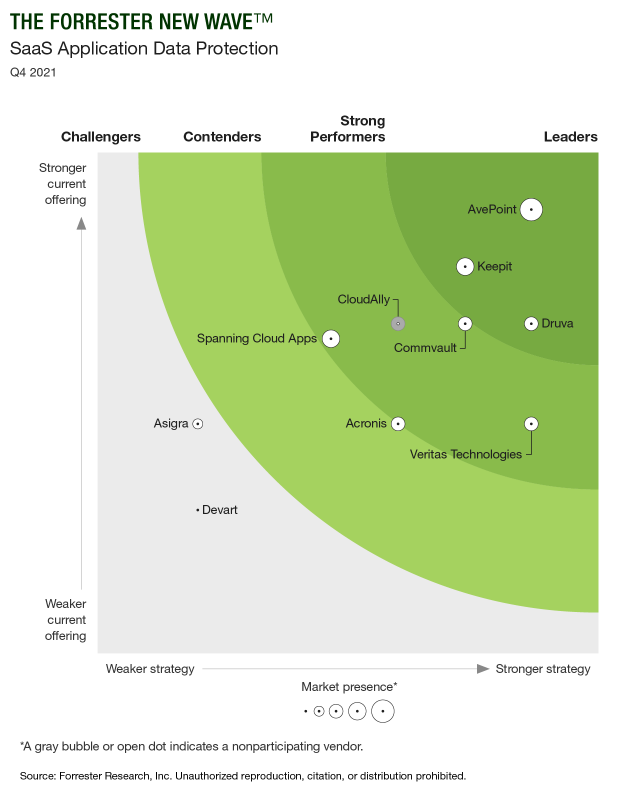
Forrester hat zehn Backup-Spezialisten zum Thema SaaS Application Data Protection analysiert. Als die wichtigsten Player auf dem Markt wurden Acronis, Asigra, AvePoint, CloudAlly, Commvault, Devart, Druva, Keepit, Spanning Cloud Apps und Veritas identifiziert. Mit großem Abstand konnte sich AvePoint als Leader durchsetzen. Das 2001 gegründete Unternehmen hat sich als eines der ersten auf die Sicherheit von Daten in SaaS-Plattformen spezialisiert.
Warum ist das wichtig?
SaaS gehört mittlerweile zur Grundausstattung eines Unternehmens. Es gibt kaum eine Firma, die nicht wenigstens Microsoft 365 einsetzt. Viele Unternehmer gehen davon aus, dass sie mit der Nutzung von SaaS-Angeboten auch gleichzeitig alles für den Schutz und die gesetzeskonforme Aufbewahrung ihrer Daten getan haben. Dem ist mitnichten so! SaaS-Anbieter stellen lediglich einen Dienst bereit. Dazu gehört zwar auch ein gewisser Cloud-Speicherplatz sowie eine Basisabsicherung der Daten, jedoch kümmern sich die Anbieter pauschal weder um Backups, Disaster Recovery noch Archivierung. Das ist nach wie vor die Verantwortung der Unternehmer.
Die große Herausforderung bei SaaS-Angeboten wie von Salesforce.com, Google Workspace or Microsoft 365 ist die gesetzeskonforme Archivierung. Zwar gibt es schon länger entsprechende Lösungen für Outlook & Co, aber wie sieht das bei Teams, SharePoint oder Chat aus? Auch Backup und Restore sind alles andere als trivial in der SaaS-Welt. Das Storage-Konsortium hat in einem Artikel alles zusammengefaßt, was Du wissen mußt.
Einen Link zum Reprint des vollständigen Reports von Forrester Research könnt ihr auf der Website von AvePoint finden.
Unsere Gedanken, Diskussion und Zusammenfassung im Podcast:



