
Das hätte Chefredakteur Kerstin nicht gedacht, dass sie gleich zweimal innerhalb eines Quartals in San Francisco ist. Im Rahmen der 42. IT Press Tour besuchten wir diesmal Firmen zu den Themen Data Processing, Datenbanken und Data Management. Es gab jede Menge AI und ML. Außerdem fanden wir gleich zwei gute Anwendungsbeispiele für Intels Optane-Technologie – wir erklärten die Technologie schon einmal in unserem Artikel über Latenz.
Tour de Valley
Die zweite Reise ins Silicon Valley führte uns diesmal quer durch die einzelnen Gemeinden von Santa Clara bis runter nach San Francisco. Besucht haben wir Alation, SambaNova, BMC, GridGain, FlashGrid, SingleStore, Observe und Hazelcast. Prinzipiell ging es um Datenmanagement und Datenverarbeitung. Wir haben viel über Datenbanken gelernt und viele nette Menschen getroffen. Wenig überrascht hat uns die allgegenwärtige Präsenz von Artificial Intelligence (AI) und Machine Learning (ML). Auch Natural Language Processing (NLP) spielt eine immer größere Rolle.
Die geforderte Rechenpower für die künstliche Intelligenz und ihre Workloads liefert spezielle Hardware. Neben GPUs sind das auch immer öfter explicit für die Anforderungen von AI & Co entwickelte CPUs. Einer davon ist SambaNova, die wir am ersten Tag besuchen durften.
Democratizing AI

SambaNova bietet Komplettsysteme auf Basis einer eigenen Prozessoreinheit. Beim Design des Chips waren vor allem die Software-Anforderungen ausschlaggebend, weswegen uns die RDU (Reconfigurable Dataflow Unit) als Software-Defined Chip vorgestellt wurde. Der Fokus liegt auf den Instruction-Sets, mit denen die RDU an individuelle Anforderungen angepaßt wird.
SambaNova-Systeme werden darüber hinaus mit vortrainierten Modellen ausgeliefert. Eine große Herausforderung vor allem im NLP sind Sprachen. SambaNova weiß das und trainiert ihre Modelle auch schon mal in Ungarisch. Für OTP – einen der größten unabhängigen Finanzdienstleister in Mittel- und Osteuropa mit über 40.000 Mitarbeitern und mehr als 17 Millionen Kunden – entwickelte und implementierte SambaNova in weniger als 3 Monaten den schnellsten Supercomputers für KI in Europa.
Ihre Verantwortung sieht das Unternehmen vor allem darin, die Technologie für möglichst viele nutzbar zu machen. „Bringing AI to the masses.“ bekräftigt Ami Love, Chief Marketing Officer bei SambaNova Systems, die Mission des Startups.
AI und ML definieren in Zukunft die Wettbewerbsfähigkeit von Unternehmen. SambaNova hat die Trends und Use Cases der AI-driven Enterprise in einem Report zusammengefasst.
Information Makes the World Go Round
Ein Anwendungsfall für AI ist Informationsmanagement. Aus ihrer eigenen Vergangenheit weiß unser Chefredakteur wie schwer sich Firmen vor allem mit der Klassifizierung von Informationen tun. Dabei ist das eine der wichtigsten Schutzmaßnahmen im Kampf gegen Datenlecks. Ohne Klassifizierung ist eine sinnvolle Umsetzung des Need-To-Know-Prinzips unmöglich. Auch die Verifizierung von Informationen ist ein wichtiger Aspekt, wenn es um Vertrauen geht. Alation hat eine Plattform zum Informationsmanagement in Unternehmen entwickelt.
Informationsmanagement mit der Plattform von Alation basiert dabei nur auf den Metadaten. Diese werden Silo-übergreifend analysiert, klassifiziert und mit weiteren Informationen angereichert. Mit einem Gamification-Element werden Anwender zur Mitarbeit motiviert und mit Badges belohnt, wenn sie z. B. beim Validieren von Information mitwirken.
Eine für Alles und Alle für Eine
Informationen sind nichts, ohne die richtige Ablage. Die meisten Informationen werden dazu in Datenbanken gespeichert. Damit sind oft gleich diverse Probleme verbunden. Auf unserer Tour de Valley besuchten wir unterschiedliche Firmen, die sich jeweils einer oder mehreren dieser Herausforderungen stellten.
Ab in die Cloud
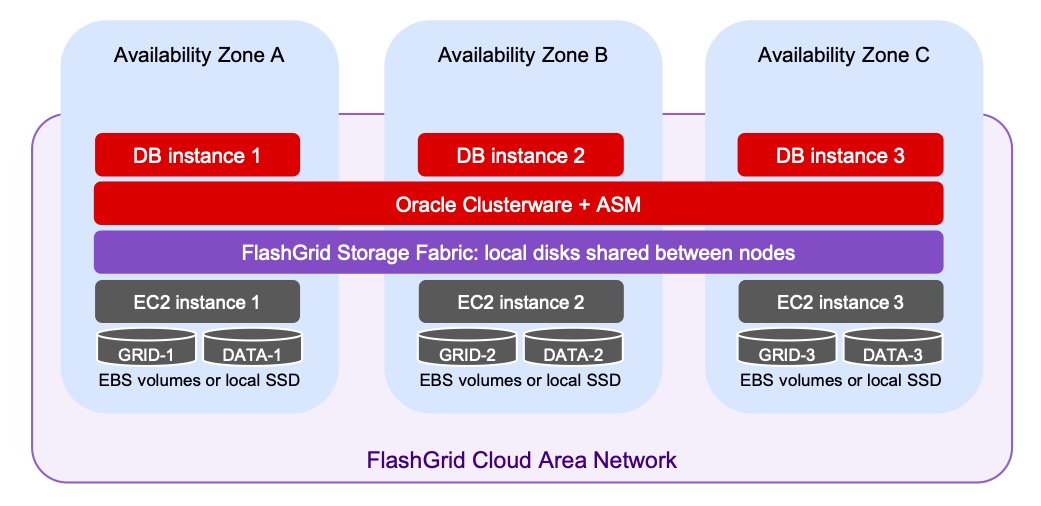
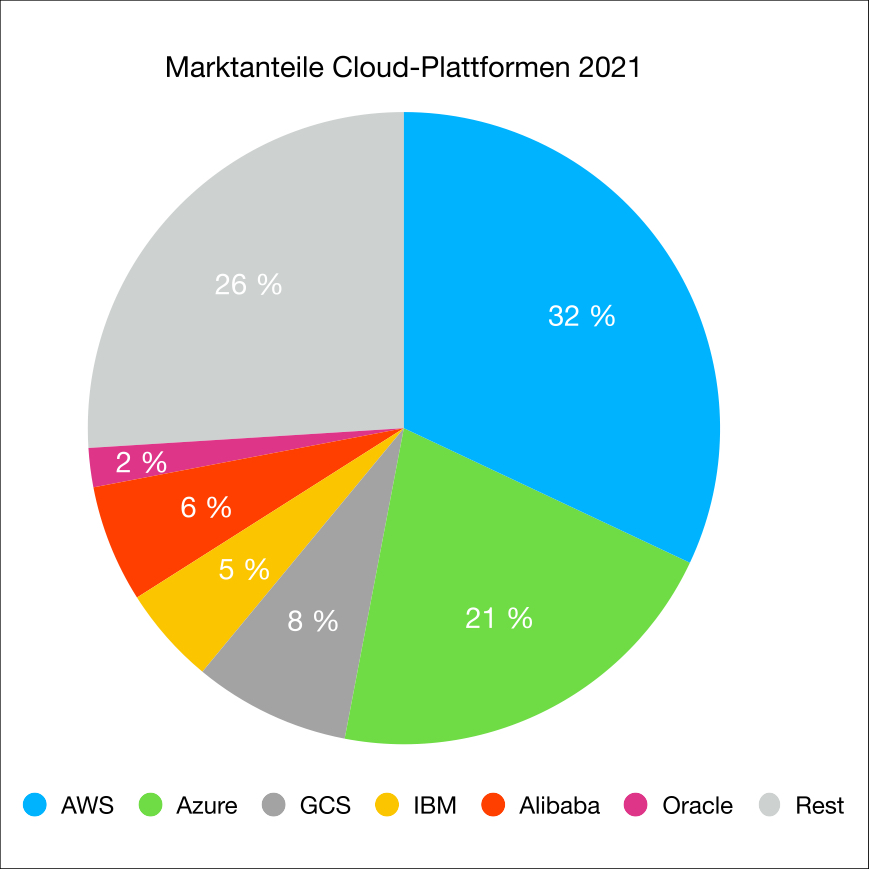
Das ist leichter gesagt als getan – zumindest, wenn es um Datenbanken geht. Zwar gehört Oracle nach wie vor zu den Markführern bei den Datenbanken, aber bei den Cloud-Anbietern rangiert der Anbieter eher unter ferner liefen. Den Cloudmarkt dominieren AWS, Azure und Google Cloud Services (GCS). FlashGrid weiß das und bietet Anwendern Software-Defined Storage (SDS) auf den Plattformen eben dieser Marktführer an. FlashGrids Angebot eines persistent Blockstorage richtet sich vor allem an FinServ, Behörden und Anbieter von Telekommunikationsdiensten.
Ein spezieller Layer fasst lokale Disks und Amazon Elastic Block Store (EBS) zu shared Pools zusammen und erhöht so Kapazität, Leistung und Ausfallsicherheit. Die Lösung gibt es für on-premises, Amazon und Azure – letztes ohne EBS. Multi-Cloud ist nur mit nativen Datenbank-Werkzeugen möglich, wie sie auch für Disaster-Recovery genutzt werden. Shared Pools cloudübergreifend geht (noch) nicht.
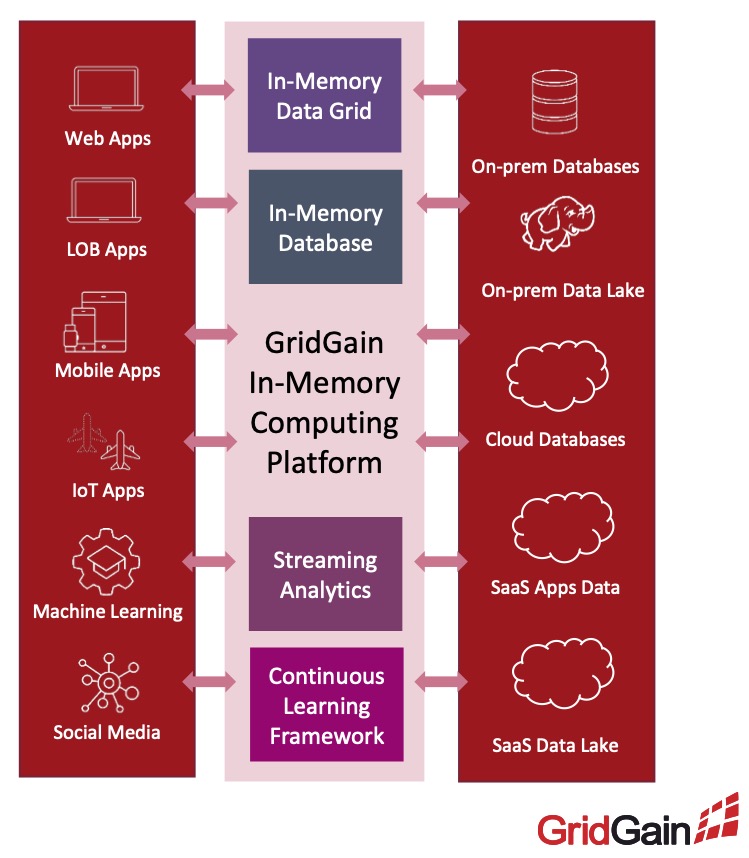
Ebenfalls Datenbanken in die Cloud – aber anders! – bringt GridGain, der Erfinder von Apache Ignite. GridGain verbindet verteiltes Datenbank-Management mit dem Vorteil einer In-Memory-Computing-Plattform für Echtzeit-Analysen über den gesamten Datenbestand. Die Lösung berücksichtigt auch Mainframes, die in vielen Bereichen nach wie vor unersetzlich sind. Der entscheidendste Vorteil der Dinos ist ihre Hardware-basierte Zeitsynchronisation. Dieser wichtige Dienst ermöglicht die Koordination von Ereignissen und Kommunikation bei Echtzeitanwendungen in verteilten Systemen. Mit der Plattform lassen sich z/OS-Anwendungen für die Echtzeitverarbeitung modernisieren. Das ist gut für den Investitionsschutz. IBM biete dazu den Z Digital Integration Hub (zDIH) an, der auf GridGain for z/OS-Plattform basiert.
Auch sonst lässt sich die in Java geschriebene Software so ziemlich auf jedem System installieren. „Unsere Software läuft auf jedem System mit einer Java-Umgebung“ sagt Nikita Ivanov, CTO und Gründer von GridGain.
Wer die Software nicht selbst installieren und administrieren möchte, sollte sich GridGain Nebula anschauen. Die Cloud-native Plattform ist ein vollständig verwalteter Dienst für Apache Ignite. GridGain bietet eine kostenlose Test-Version.
GridGain war übrigens eine von zwei Firmen, die ein Hotel für die Präsentation gemietet haben. Zwar gibt es noch ein Lab, das auch als Firmensitz dient. Allerdings hat das Unternehmen während der Pandemie ihre eigenen Räume im Valley aufgegeben und ist seitdem remote only. CEO Abe Kleinfeld war anfangs skeptisch und ist immer noch begeistert davon, wie einfach die Umstellung war. das zweite Unternehmen, das wir in einem Hotel trafen, ist Hazelcast. Hazelcast setzte von Anfang an auf eine Remote-First-Strategie.
Mainframes begegneten uns auch bei BMC, die Mainfames in ITOM/ITSM-Landschaften integrieren, mit AI, ML und Predictive Analytics automatisieren und sicherer machen. Das Flagschiff des Unternehmens ist allerdings die Helix-Plattform. Die gibt es ab sofort auch als Cloud-Service. Entschieden hat man sich dabei für den Oracle Exadata Cloud Service auf Basis der Oracle Cloud Infrastructure (OCI). Chad McAfee, Group Vice President ISV and Cloud Native bei Oracle, erklärte die Entscheidung mit „There is need on both sides.“ Oracles Anteil am globalen Cloudmarkt dürfte BMCs Wahl gefallen.
Die vollständige Palette gibt es auf der Homepage des Anbieters. Uns überforderte das Angebot und wir schauen weiter auf die Evolution des In-Memory-Computing.
Wie GridGain setzt auch Hazelcast auf In-memory-Computing in der Cloud. Dazu ging das Unternehmen u. a. eine strategische Partnerschaft mit Intel ein. Das Unternehmen mit Sitz in Istanbul integriert Transaktions-, Betriebs- und historische Daten in eine einzige Plattform. Die Lösung ist cloud-native und kann mit Standard-Werkzeugen (Kubernetes, Red Hat OpenShift) selbst verwaltet, als managed Service in AWS, Azure und GCP betrieben, embedded in Appliances (z . B. Netzwerk-Monitoring, XDR, etc.) oder am Edge installiert werden. Kelly Herrell, CEO bei Hazelcast, berichtet „ein Kunde soll es sogar auf einem Raspberry Pi installiert haben.“
Daten gelangen über Standardschnittellen (APIs) in und wieder aus der Plattform. Kunden können eigene Anwendungen programmieren oder bestehende verknüpfen. Anwendungen müssen nicht selbst Storage-Class Memory (PMEM) unterstützen. Auch Hazelcast hat einen Abstraktionslayer in seiner Plattform, mit dem jede Anwendung von den Vorteilen des In-Memory-Computing profitieren kann. Zu den Anwendungsbereichen gehören vor allem Echtzeitanwendungen im Finanzsektor und im E-Commerce, das Internet of Things (IoT) sowie AIOps.
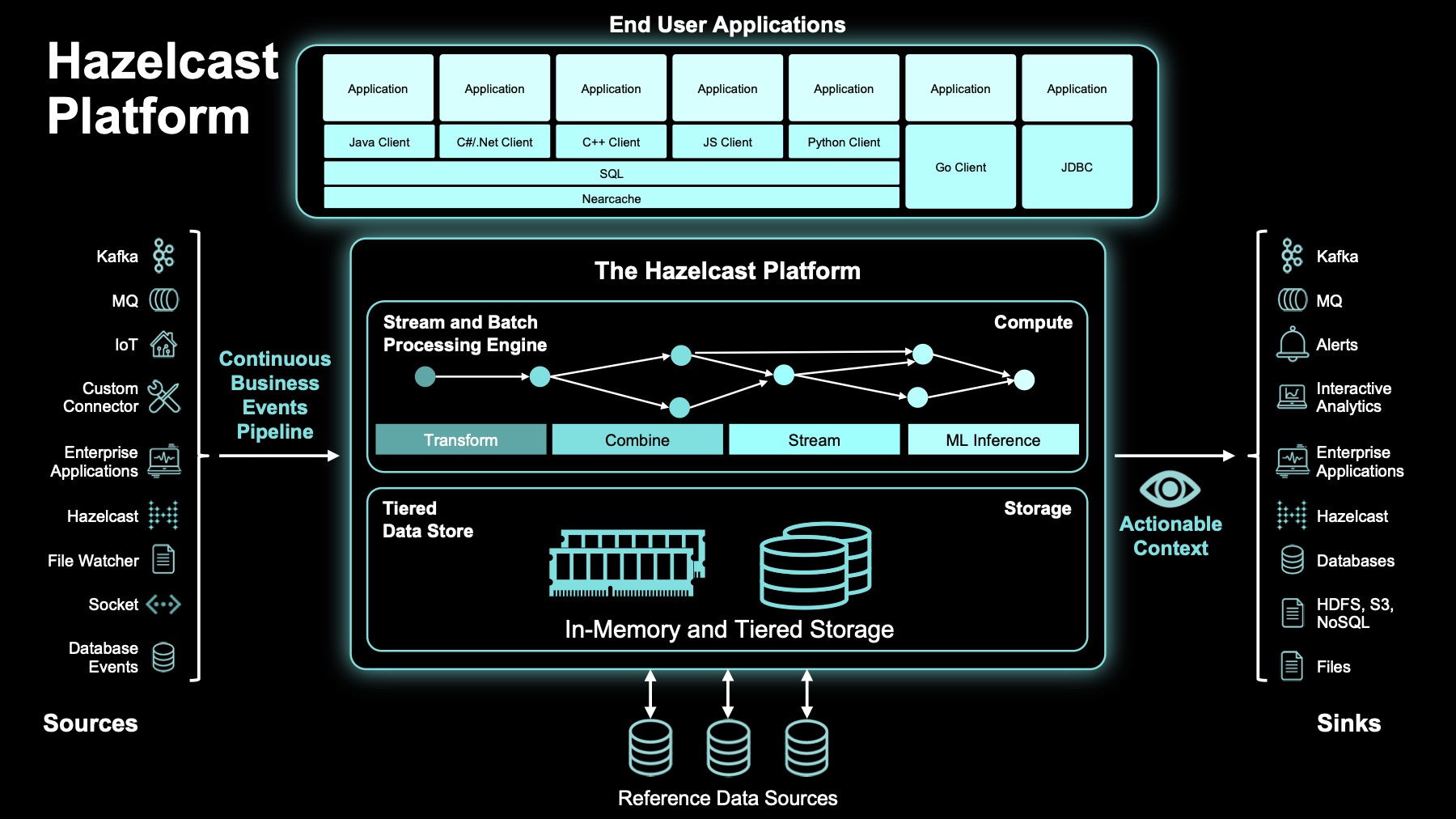
Selbstverständlich bietet auch Hazelcast einen kostenlosen Test seiner Plattform an.
Ein Name tauchte in fast allen Präsentationen auf: Snowflake. Das Data Warehouse as a Cloud Service wurde mal als Marktbegleiter, mal als Technologie-Partner oder auch nur als Beispiel genannt.

2020 wurde Observe von Snowflake als innovativste Datenanwendung des Jahres ausgezeichnet. Das Startup war als Einziges von den von uns besuchten Unternehmen auf SMB fokussiert. Gerade kleinere Unternehmen können oder wollen sich oft keine teuren Analyse-Plattformen leisten. Dabei ist gerade für KMU der Service so wichtig. Ein Instrument dazu ist Troubleshooting. Wäre es nicht toll, dem Kunden schon zu helfen, bevor er überhaupt weiß, dass er ein Problem hat? Observe hat eine Analyse-Plattform entwickelt, das wie Snowflake auf Credits basiert, und genau diesen Markt adressiert.
Eine weitere große Herausforderung in KMU ist der Fachkräftemangel. Ein Kubernetes-Experte weiß, dass Container-Logs von Containern in Pods auf Nodes erzeugt werden. Aber ein Golfplatzbetreiber, dessen CRM in AWS in einem solchen Container läuft, versteht wenig davon. Einer der Vorteile des Observe-Portals sind Ausgaben und Alarme in menschen-verständlicher Sprache. Das Portal eignet sich außerdem für die Investigation. Das ist z. B. nach einem Sicherheitsvorfall unerlässlich.
Jetzt brauchen aber all die Transaktionen und Analysen nach wie vor Daten, die zumeist in Datenbanken organisiert sind. Und weil es so viele unterschiedliche Datenbanken gibt, gilt nach wie vor: je mehr Daten, desto komplexer die Landschaft. Daten werden in Spalten, Zeilen, Würfeln, relational, nicht rational, transaktional, analytisch oder in Clustern organisiert. Entsprechend groß ist Vielfalt, seine Daten in eine einzige Analyse- oder Transaktionsplattform zu bekommen. Ein bisschen MySQL hier, viel MariaDB da, etwas NoSQL dort und hier vielleicht noch eine Portion Postgres, etc. Wer also sowieso gerade nach einer neuen Datenbank sucht, sollte sich einmal SingleStore anschauen.
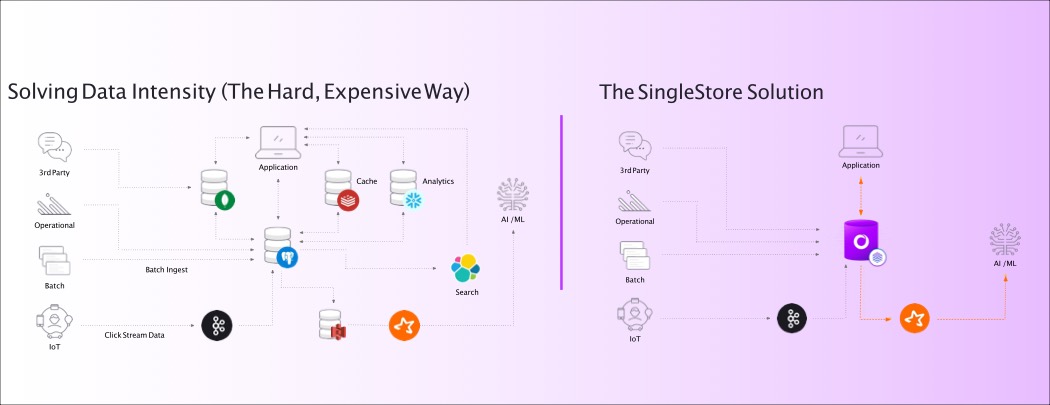
Analytical. Transactual. Mir doch egal!
SingleStore verbindet Spalten und Zeilen zu einer einzigen translytical Database.

SingleStore ist eine Datenbank für alles: egal ob strukturiert, halb-strukturiert oder unstrukturiert. Dieser Datenbank ist das egal. Das vereinfacht die Infrastruktur im Unternehmen immens. Aber das ist noch nicht alles. SingleStore ist cloud-native und holt das Beste aus RAM und CPU heraus.
Ein Abstraktionslayer sorgt dafür, dass Anwendungen die Vorteile von In-Memory-Computing nutzen können. Das beschleunigt die Transaktionen oder Analysen ohne vom darunter liegenden Storage limitiert zu werden. Dazu hat das Unternehmen einen eigenen Storage-Layer entwickelt.
Statt REST-API setzt die Lösung auf HTTP zum Datenaustausch. Es werden keine SDKs benötigt.
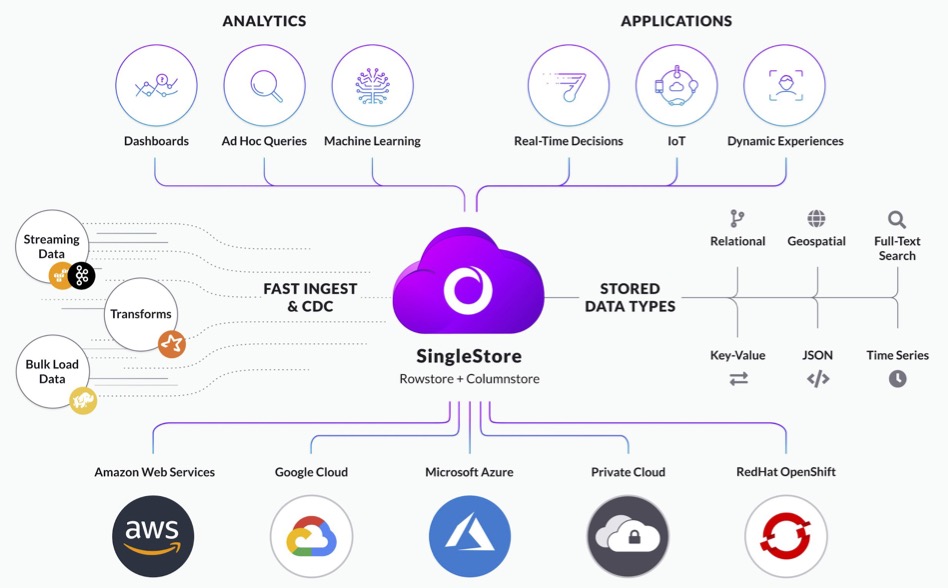
SingleStore ist u. a. zertifiziert nach ISO/IEC 27001, SOC 2 Typ 2 und Privacy Shield und vollständig konform mit den Anforderungen von CCPA und GDPR. In den Versionen Premium und Dedicated erfüllt SingeStore ebenfalls die Anforderungen von HIPAA-Workloads. Mehr zur Sicherheit von SingleStore gibt es in einem White-Paper.
Zu den Investoren gehören IBM, HPE und Dell. Wer es testen möchte, kann sich auf der Website für einen kostenlosen Test anmelden.
Fazit
Datenmanagement und Data Processing sind heiße Themen. Ein Blick auf die neuen Anbieter lohnt sich für alle, die sowieso gerade ihre Datenstrategie überdenken und die Digitalisierung ihres Geschäftsmodells anstreben. Je nach Anforderung kommen verschiedene Lösungen in Betracht. Für Systemhäuser bietet sich hier eine einmalige Gelegenheit sich entweder als Berater zu etablieren oder als Integrator für ganz bestimmte Use Cases. Service Provider können die Plattformen für eigene Services nutzten: fast alle der vorgestellten Lösungen sind mandantenfähig. Wir werden uns den ein oder anderen Anbieter noch genauer anschauen und für euch analysieren. Unsere Kommentare und Diskussion zu den einzelnen Anbietern gibt es im Podcast.

